
Abstract
Swin Transformer aims to introduce Transformer into computer vision as a general-purpose CV backbone, and even as a replacement for CNNs. Considering the different characteristics of text and image tasks, the main idea of Swin Transformer is a hierarchical Transformer based on shifted windows. Swin constrains self-attention computation within non-overlapping windows, while still allowing cross-window connections. This makes it more efficient, and its complexity grows linearly with image size. Experiments show that replacing CNNs with Swin improves performance on many CV tasks. Swin code link
Introduction
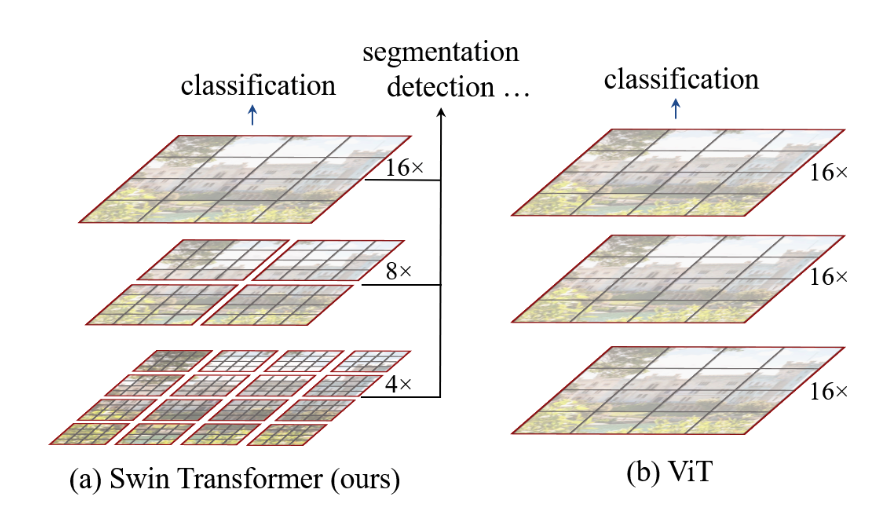
Swin is similar to a multi-layer CNN: it gradually summarizes neighboring “attention” regions layer by layer. In each layer, the image is divided into multiple local windows, and each local window contains multiple patches. A local window is the smallest unit, somewhat like a convolution kernel. In each layer, self-attention is computed over local windows composed of patches. Therefore, the complexity is linear. Previous vision Transformers performed self-attention over the whole image, which led to quadratic complexity.
The main challenge in transferring Transformer from NLP to CV lies in the difference between the two modalities. The first difference is scale: the basic processing unit of text is usually a token in a sentence, while the unit of an image is a large number of pixels. The number of text tokens can be relatively fixed, but image resolution can vary greatly. The second difference is resolution: the complexity of Transformer on high-resolution images is quadratic. Swin Transformer is proposed to address these issues. It can construct hierarchical feature maps while maintaining linear complexity.
In addition, the key design of Swin is the shifted window. Shifted windows build connections among local windows between adjacent layers.
Method
Overall Process
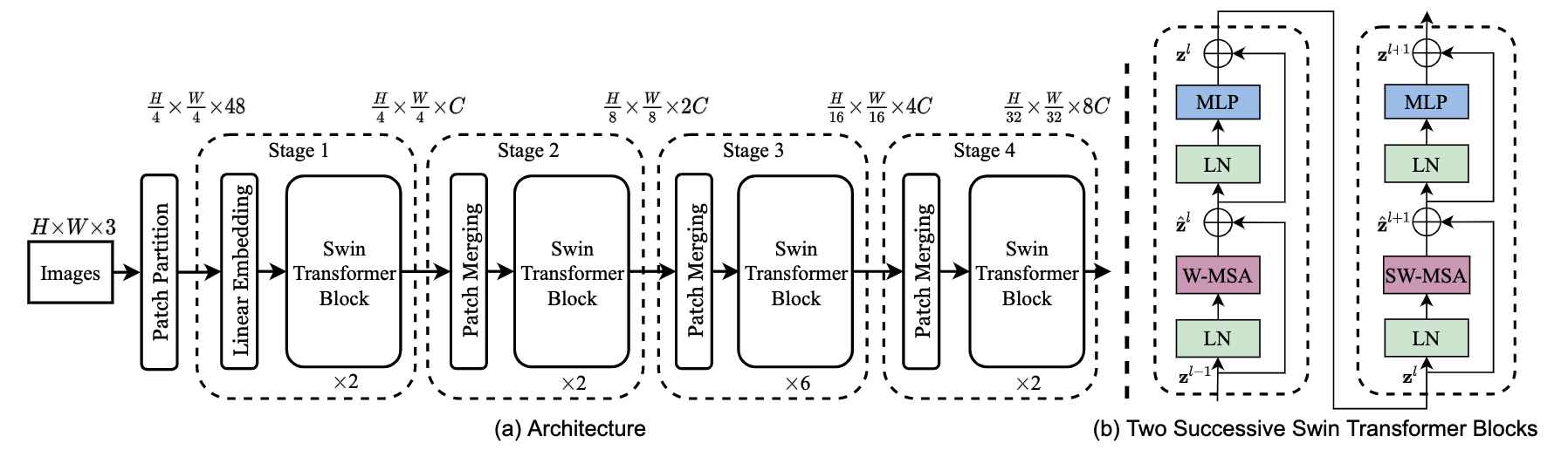
- For an RGB image, the image is divided into multiple $4\times 4$ patches. Each patch plays a role similar to a token. The patch is concatenated into a $4\times 4\times 3=48$ dimensional feature. After a fully connected layer and Swin Transformer blocks, it can be mapped to feature vectors of arbitrary dimension. In this way, the image is divided into feature vectors of size $\frac{H}{4}\times \frac{W}{4}\times C$.
- As the network grows deeper, a patch merging layer is used to integrate feature information from four neighboring patches in the same local window, while increasing the feature dimension of each token.
- Then, Swin Transformer blocks compute attention over patches, or tokens, within each local window. There are two types of Swin Transformer blocks: ordinary window MSA and shifted-window MSA.
- W-MSA: compute attention among multiple patches in the same window.
- SW-MSA: shift the windows to capture attention across windows.
Shifted-Window Swin Transformer
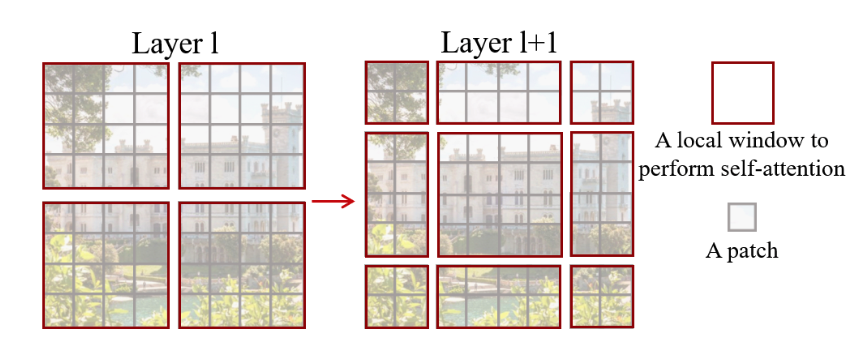
Dividing the patches of the whole image into multiple windows can effectively reduce complexity. However, computing attention only within independent windows cannot capture information between windows. Therefore, the shifted-window mechanism is introduced.
Between two adjacent Swin Transformer blocks, as shown in the figure above, the window positions are shifted. The specific shifting strategy is described below. After shifting, attention is still computed within each window, but the result now contains shared information from previously neighboring windows.
The specific shifting strategy is called cyclic shift. The window size remains unchanged between adjacent Swin Transformer blocks. The window regions are shifted, but after shifting, the number of windows increases and the size of some window regions changes. Therefore, non-adjacent windows need to be supplemented and corresponding masks need to be computed, so that only information from adjacent windows is used.
The cyclic-shift strategy is referenced from Zhihu.

Meaning of Shifted Windows
The work most closely related to Swin Transformer is ViT, which also attempts to introduce Transformer into CV by dividing images into patches and applying attention. The problem is that computing attention globally over all patches in an image has high complexity.
Swin Transformer improves this by grouping divided patches into different windows, borrowing the idea of locality from CNNs: attention is computed at the window level. However, this alone cannot obtain global information like ViT. Therefore, after computing attention within local windows, shifted windows are designed to obtain information from neighboring windows. With the hierarchical structure of the network, as the network depth increases, shifted windows can gradually capture global information from the image.
The goal of Swin Transformer is to design a general-purpose CV backbone to replace CNNs, and to achieve stronger state-of-the-art performance by replacing CNNs with Swin Transformer across various CV tasks.