Adversarial Attack
- 对于训练后的网络,是否具备鲁棒性来应对恶意输入,防止模型被“糊弄”
- 希望网络不仅具有 高准确率,还需要能够具有应对恶意输入的被欺骗能力
- 对于原始图像 Benign Image,对每个像素添加微小杂质生成 Attacked Image,使得模型的分类结果产生错误。
- 攻击分为 Targeted 攻击和 Non-Targeted 攻击,区别是是否预定模型错误的估计。
攻击方法
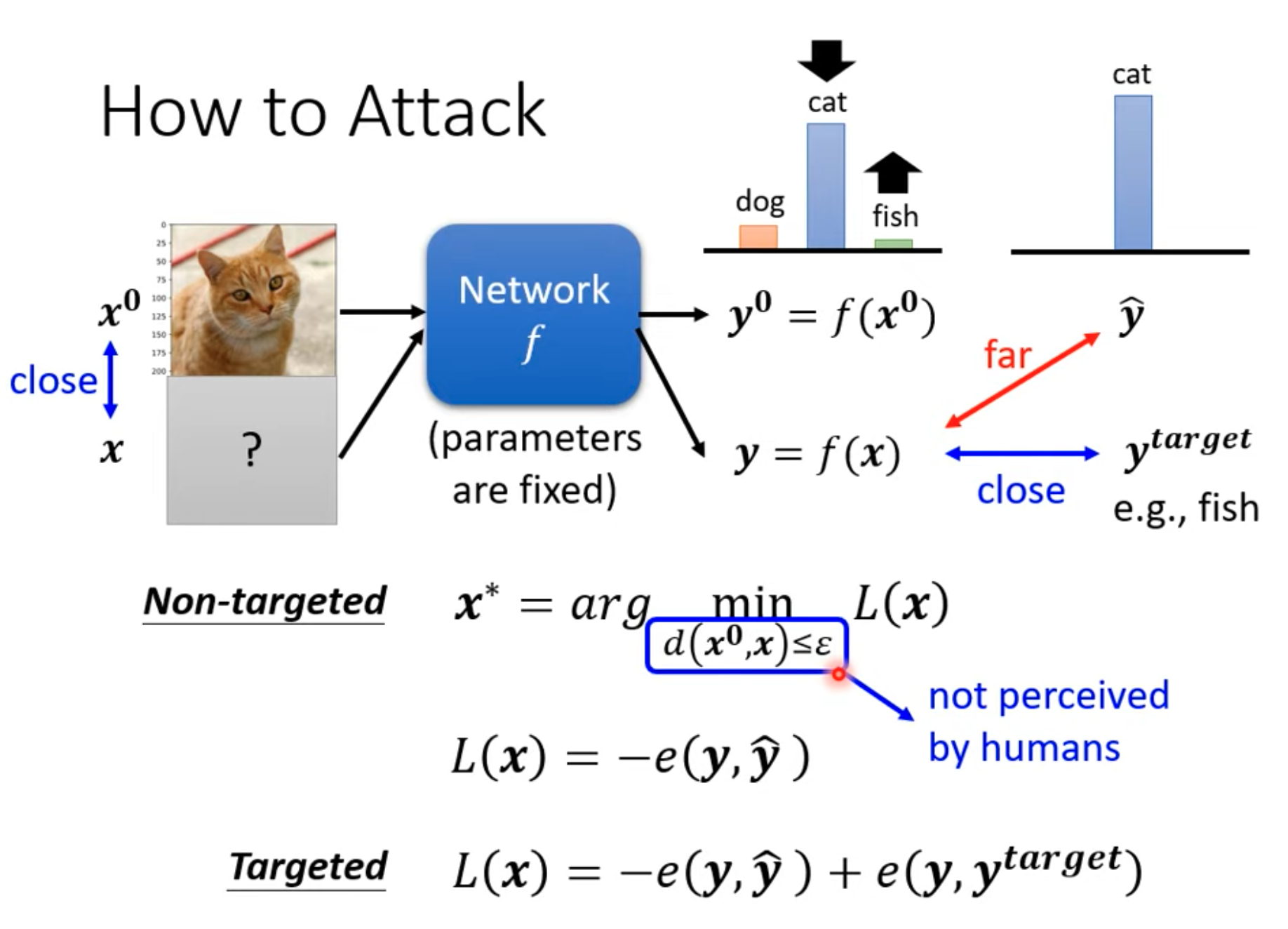
-
对于欺骗的模型,由于是在模型部署时进行欺骗,所以可以不考虑模型参数,将之固定
-
对于输入的原始图像 x0,输出 y0.对于攻击图像 x,输出为 y。对于真实的数据标签是$\hat{y}$,我们希望攻击图像得到的输出 y与$\hat{y}$的距离尽可能大,这样的损失函数可以定义为“负交叉熵”。另一方面,也希望攻击图像与原始图像尽可能相似,就需要使得$d(x^0,x)≤ \epsilon$,即图像距离小于一个阈值。可以是 最大差距或者差值均方等距离。、
- L2-norm:差值平方和
- L-Infinity: 差值最大值
- 将一副图像的所有像素都调整一点,跟将图像的某个像素作较大调整,可以得到相同的 L2-norm,但是 L-infinity 差别很大。
- 从人的主观感觉来看,对多个像素进行小的调整,更加不易分辨
-
而对于有目标攻击,我们希望攻击图像的标签与真实标签尽可能大,与 target标签尽可能小
-
我们固定模型参数,要生成攻击图像,就是根据损失函数获得。这里的损失函数和之前模型训练时一致,只不过这里的参数是得到输入 x
-
对于模型训练时:$w^,b^=arg\ \underset{w,b}{min} L(y,\hat{y})$
-
对于生成攻击图像时:$x^*=arg\ \underset{x}{min}\ L(x)$
-
使用梯度下降得到 x:
- 初始输入图像是真实图像 x0
- for t:
- $x^t \leftarrow x^{t-1}+\eta \frac{\partial L(x)}{\partial x}$
- if $d(x^0,x^t) > \epsilon$
- $x^t\leftarrow fix(x^t)$
-
-
上面我们使用梯度下降求解攻击图像,计算梯度的过程需要知道模型的参数,因为$g=\frac{\partial L(x)}{\partial x},L(x)=-e(y,\hat{y}),\hat{y}=f_{\theta}(x)$,这里的$\theta$就是需要知道的模型的参数。这种获得进攻图像的方式我们称之为「白盒攻击」,因为需要知道模型的参数。与之对应的就是『黑盒攻击』。
黑盒攻击
- 假设对于一个模型我们不知道他的参数,但是知道训练该模型的数据集。那我们就可以用这个数据集去训练一个我们自己的网络,其架构可以和要攻击的网络不同。这样的网络称为 Proxy Network。再使用白盒方式利用 Proxy Network 计算攻击图片,就可能对原本的模型进行攻击
- 如果不知原模型的训练集,可以对该模型输入许多图像获得对应的输出标签,然后用这些图像+标签作为数据集去训练我们的 Proxy network,也可以实现攻击的效果。
- 使用黑盒攻击一般只做 non-target attack
- 攻击是容易实现的
- 黑盒白盒攻击的成功率较高
- 可以对某个像素改变完成攻击
- 可以使用一个变化对多类别图像攻击
- 可以在物理世界,获得攻击:如人脸识别时戴特制眼镜、信号牌修改等
- 模型后门:在模型训练时添加 特定图像,其标签主观上也是正确的。模型使用该数据集训练后,在实际图片分类时,如果遇到某一张图像(不一定是训练集中的特定图像),就会分类错误
防御方式
被动防御:
- 在图像输入模型之前加入一个 Filter,可能是对输入图像很简单的处理
- 如 smooth 模糊处理,就可以很大限度 的避免攻击。因为攻击图像中的攻击信号是非常特殊的,一旦模糊,就会影响攻击信号。
- 对图像作压缩,再解压
- 等等
- 加入 Filter 也容易被破解。因为 Filter 可以视为模型的隐层,如果攻击者知道 Filter 的具体方式,在生成攻击图像时也加入 Filter,就可以获得对应的攻击图像。
- 与之对应的,防御时进行随机方式的 Filter
主动防御:
- 一开始就训练不容易被攻击的模型 Adversarial training,使得模型具有鲁棒性
- 主要思想是对于训练集 (X,y),训练模型后使用白盒攻击的方式获得攻击图像X',对攻击图像标上正确的标签获得 数据集(X‘,y),进而将先后两个数据集合并(X+X', y)重新训练模型。可以重复作多次
- 这种思想也可视为图像增广Data Augmentation
- 计算过程非常耗费计算资源