generator 生成式模型
生成式模型基本结构
- 与传统的输入 x 输出 y 的判别式模型对比,生成式模型还会有一个随机生成的 z 作为输入,这个 z 从某种分布中随机生成,network 同时根据 x 与 z 生成 y
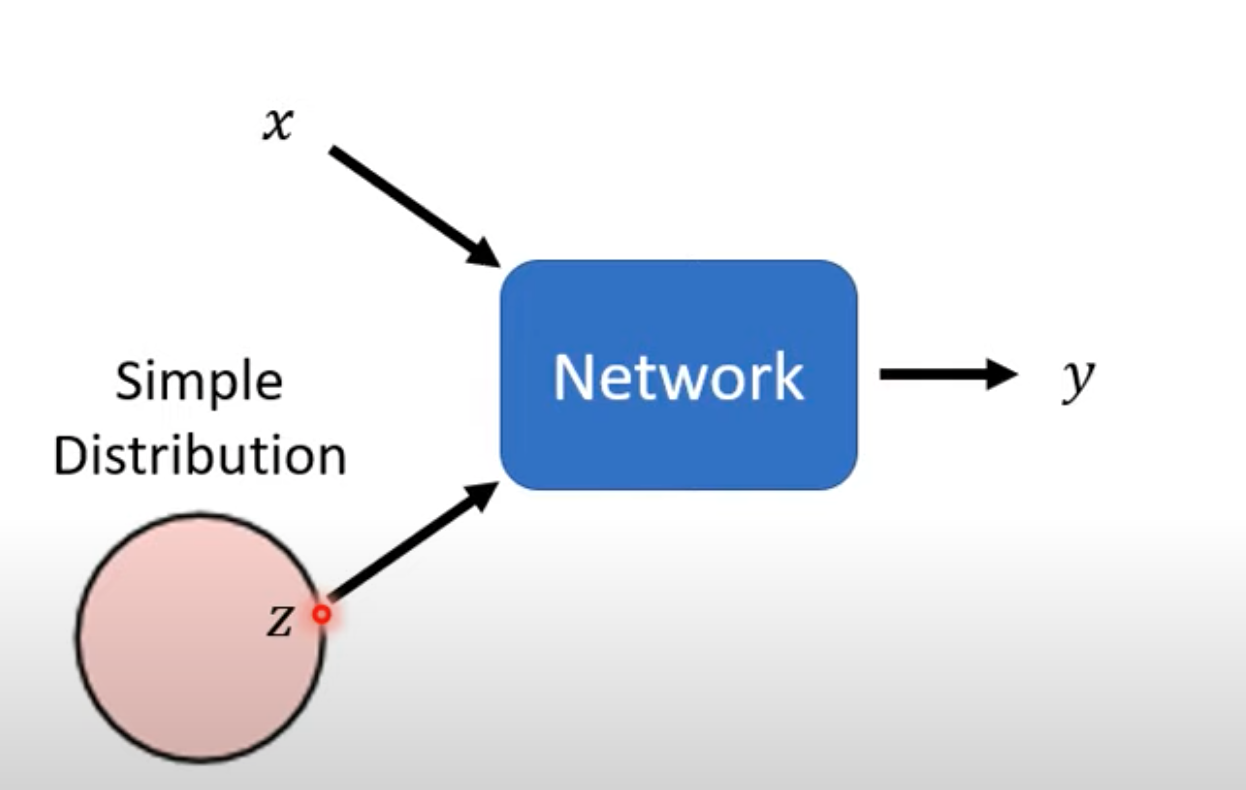
- 每一次 输入 x,都会生成一次 z,这个 z 的分布必须够简单,即需要知道 z 的表达式。例如 z 属于高斯分布、平均分布等
- 这样同样的x,输出的 y 也不相同,y 也需要属于某种分布
为何需要生成式模型
-
对于视频预测问题,训练集是从视频中提取的某些帧,模型输出入下一帧的画面。
-
倘若视频是宝可梦游戏,视频中移动的物体会存在右转或左转的情况。对于这种训练数据,左转右转对于判别式模型来讲都是正确的 case,模型为了最大化正确率输出就会平衡左转右转的情况,导致训练结束的模型无法正确理解左转右转。
-
也就是说左转右转把判别式模型绕晕了,因为都是正确的 case,模型不知如何判断,两面讨好
-
而对于生成式模型,输出会根据输入的概率分布 z 辅助判断。一定几率模型判断右转,一定几率判断左转,不会导致。输出不再固定,是一个分布
-
对于特定场景:同样的输入可能有多种输出,而这些输出都是正确的,需要模型自己判断,这时就需要一种随机概率 z 发挥模型的「创造性」
-
模型画图任务需要「创造性」;问答 chatbot 也需要「创造性」
Generation adversarial network (GAN)
GAN 示例
Unconditional generation 二次元任务面部输出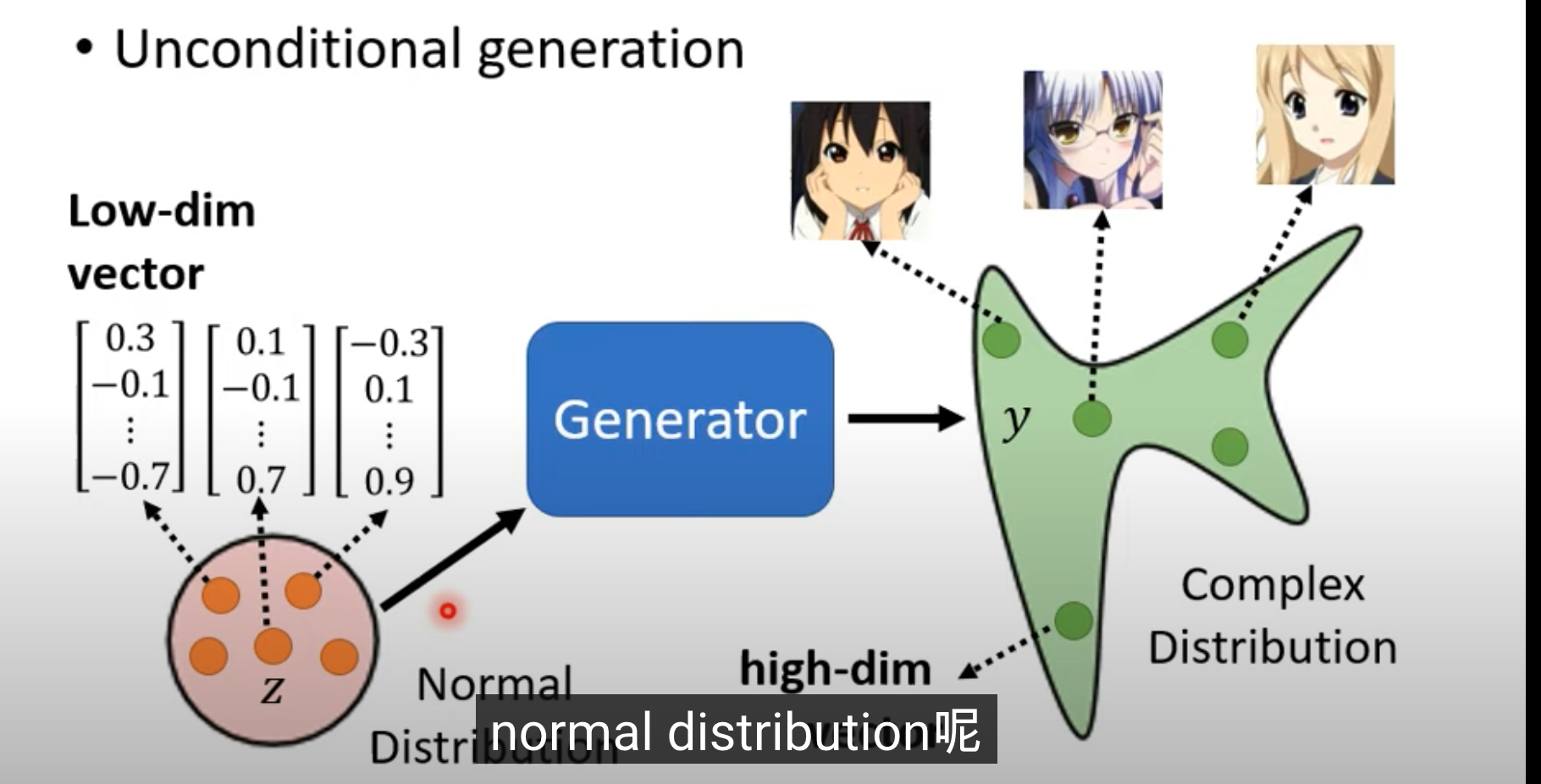
- 先不考虑 x,输入只有一个 normal 分布的 z,z 是一个简单的向量。模型根据不同的 z,输出不同的图片。假设图片是 64*64 彩色图片,输出就是 64*64*3 的向量
- 除了 generator 还需要一个 discriminator,也是一个神经网络,如 CNN、Transformer 等网络结构都可以。它输入是一张图片,输出是一个 scalar(数字)。对于某个输入图片,输出的 scalar 越大,说明图像越符合我们想要的
gan 思想
- 类似于动物演化、适者生存的思想。鸟吃彩蝶,彩蝶变褐色蝶;鸟开始根据纹路,也开始吃褐蝶;褐蝶变枯叶蝶,鸟开始分辨枯叶蝶与真正的枯叶
- 这里蝴蝶的演化是 generator,鸟的角色就是 discriminator。
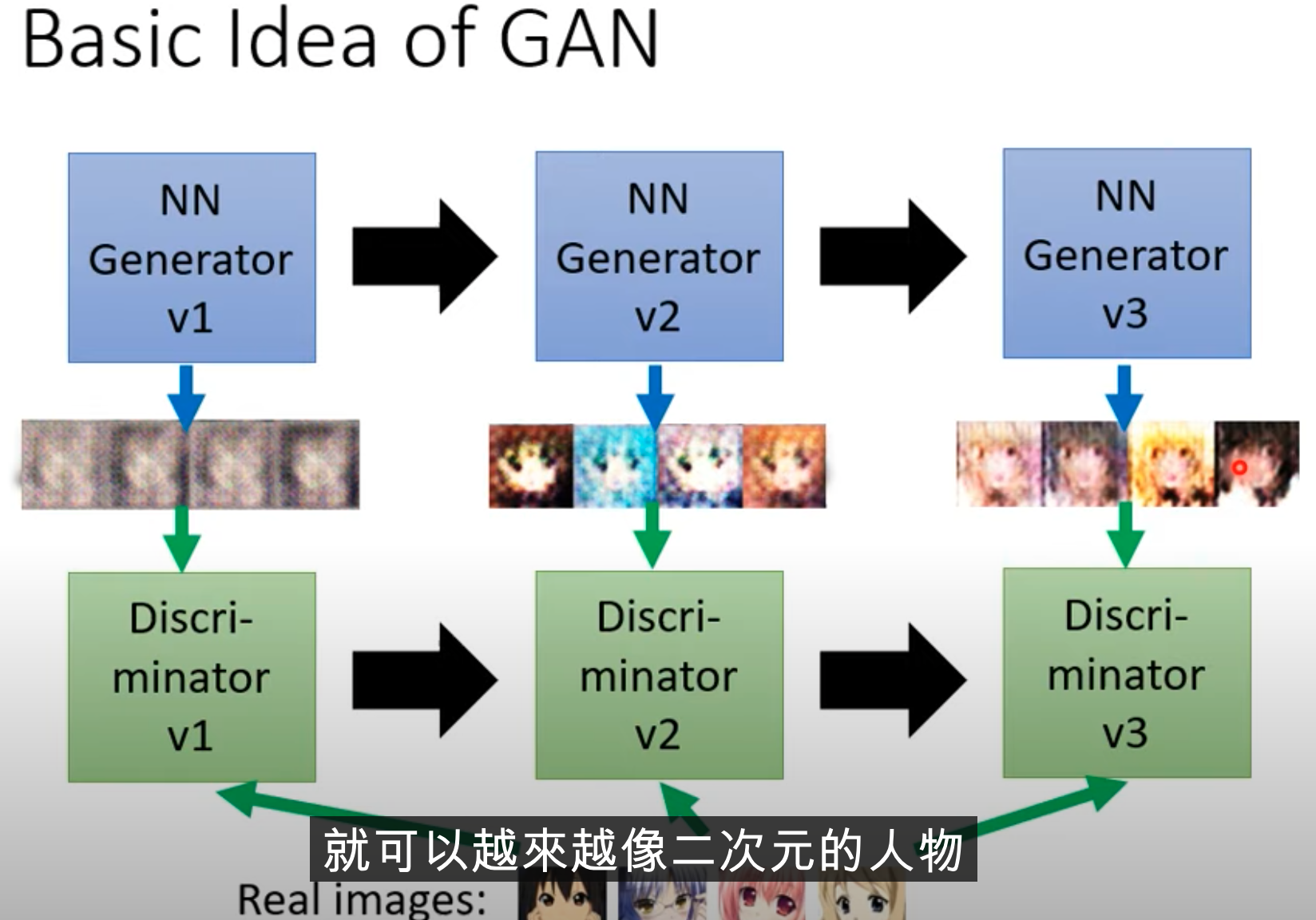
- 首先生成器随机生成 case,判别器与真实图像对比,通过是否有眼睛判断生成的图像是否真实。生成器据此随机生成有眼睛的图像;判别器再根据是否有嘴巴头发判断图片真实程度。如此循环演化。
对抗算法
-
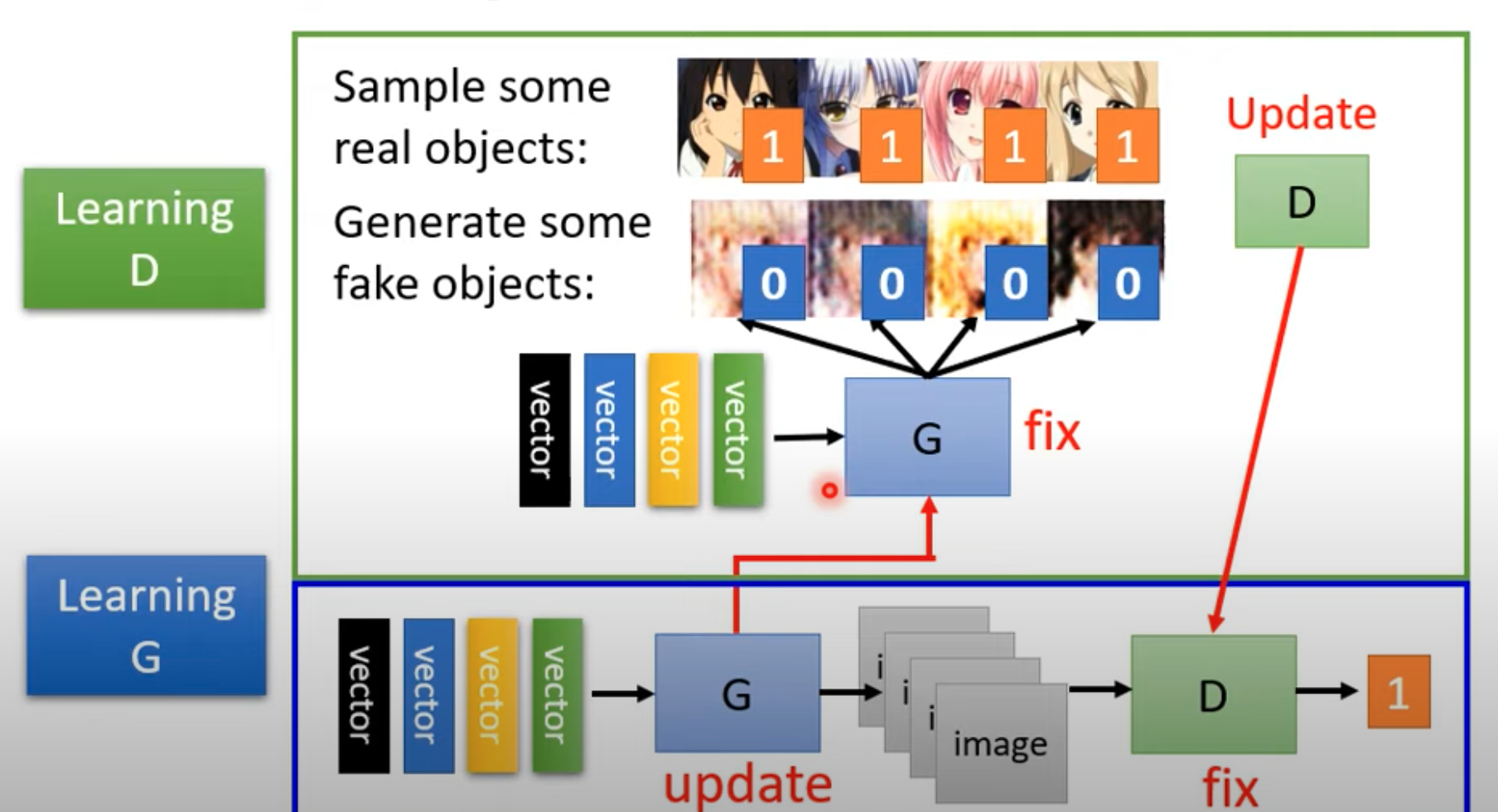
初始化参数,生成 generator 与 descriminator
-
对于每次训练,先训练判别器:
- 固定生成器,更新判别器。其中,生成器输入是随机分布的 z,根据随机参数输出图像 。
- 根据真实图像和生成器输出图像,训练判别器图像,使之能够分辨两种图像的真假。具体方法可能是真实图像标签都为 1,生成器输入图像都标 0;如此对于判别器的工作就可以视为回归问题或二分类问题
-
然后训练生成器:
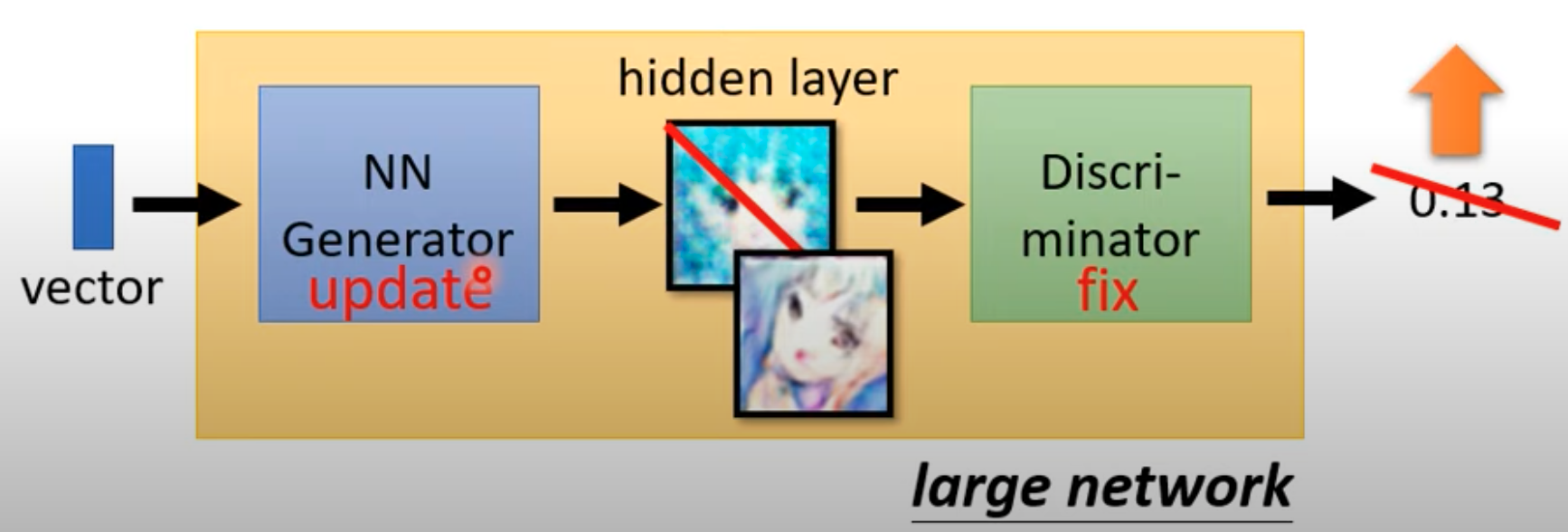
- 固定判别器参数,更新生成器参数,目的是使得输入随机 z,生成的图像能够“欺骗”判别器
- 欺骗判别器可以当成使得生成的图像输入判别器,判别器输出的 scale 尽可能大
- 具体过程我们可以连接生成器和判别器网络成一个“大网络”,将生成的图像当做大网络的隐藏层,这个大网络的输入是随机的 z,输出是判别器的分辨分数
- 这样训练一个大网络,更新前半部分生成器参数使得最终输出尽可能大(这样的 Loss 函数需要特别设计)
-
如此循环,分别训练生成器和判别器
GAN 理论分析
GAN 训练的目标
-
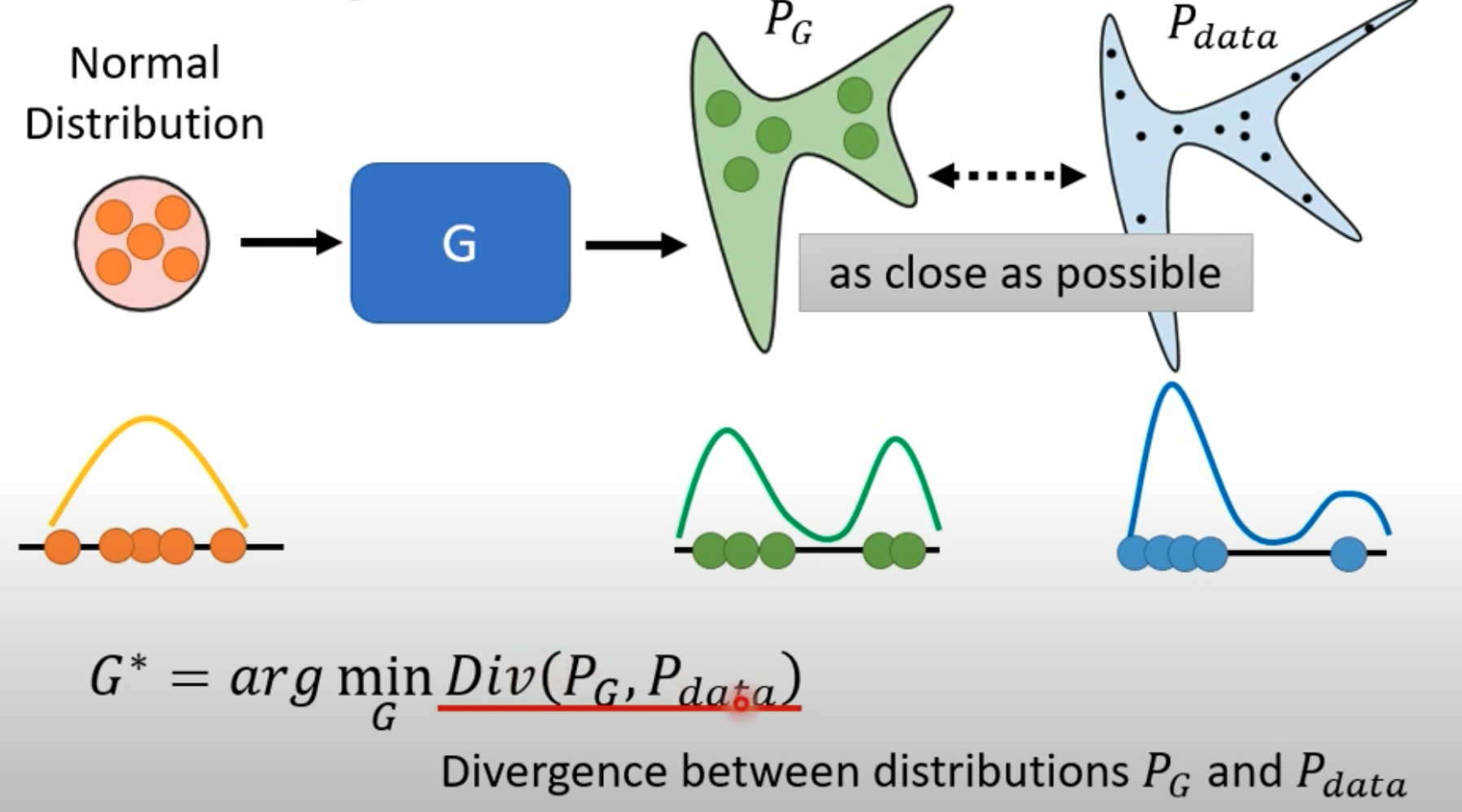
对于从一个满足随机分布的向量 z,输入到生成器输出一个随机分布 Pg,我们希望让生成的 Pg 和真是的数据 Pdata 的分布尽可能接近。
-
Divergence 指两种数据分布的距离,类似 KL 距离、JS 距离等很多距离公式。一个主要问题是如何根据两种数据计算这个 Divergence。因为 Pg 和 Pdata 的是两种数据集,规模大,不好计算。训练的过程就是去 train 这个 Divergence
-
GAN 面对这个问题是从 Pg 和 Pdata 随机取样 sample。从 Pdata就是从真实数据集中取样;Pg 就是根据已知分布的 随机向量 z 从生成器随机生成。 这里的生成器就可以视为 Pg 的 dataset
-
GAN 就是靠 Discriminator,根据从 Pg 和 Pdata 随机 sample 的样本,估计出了 Divergence 的计算方法
- 判别器的任务就是对于输出的数据,分辨出真实图像和生成的图像
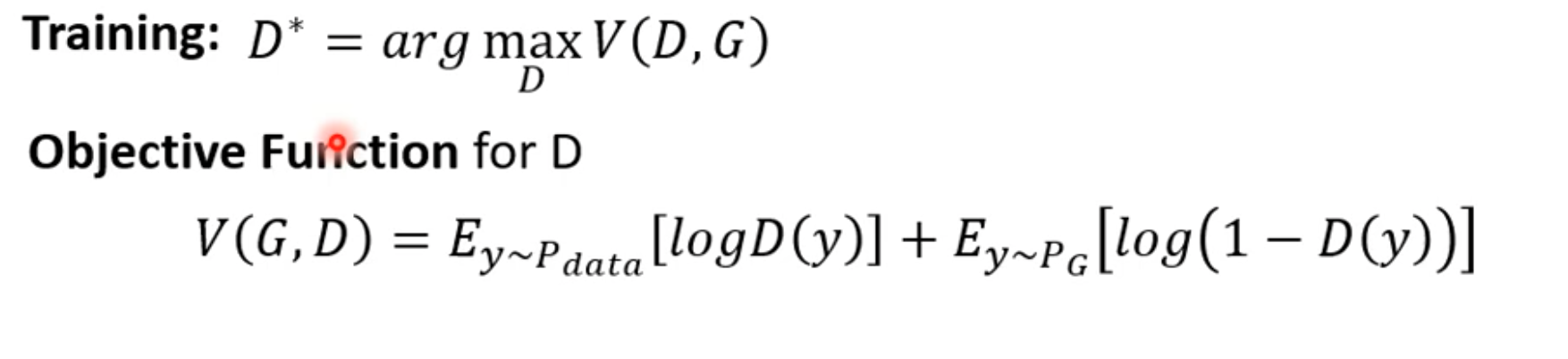
- 这种做法就想训练一个二元分类器,我们希望训练的分类器使$V(D,G)$越大越好。
- 这里的$V(D,G)$可以是**‘负’交叉熵**。因为对于二分类问题,我们的目标是想最小化交叉熵。所以在这里的负交叉熵,就是希望最大化。、
- 所以最关键的一点就是,无论使用何种方式训练判别器,我们的目标是要「最大化」判别器的损失函数
- 最重要的神奇的点是,将分类器作为分类任务,计算$max_D V(D,G)$最大值时,值经过推导后,与 JS Divergence 是有关的。也就是说,在计算生成器 Pg 与 Pdata 的 Divergence 比较困难时,我们根据判别器的损失函数优化到最大值时,可以获得当前 Divergence 的评价效果
- 具体推导可以看 goodfellow 的开山论文,但从直观理解,生成图像和真实图像,即 Pg 和 Pdata,越相似,对于判别器的就越难分辨,得到的$max_D V(D,G)$相对较小,这时对应的 Divergence 也就越小
-
总结一下就是,我们的生成器训练目标$G^*=arg\ min_G \ Div(P_g,P_{data})$,而给定 Pg 和 Pdata,无法直接计算 Div(Pg, Pdata)。所以我们采用间接的方法:通过判别器分辨 Pg 和 Pdata,判别器的训练目标是$D^*=arg\ max_D\ V(D,G)$,这里的$max_D\ V(D,G)$和 $Div(Pg, Pdata)$是存在正比关系的,即判别器 D 越难分辨 Pg 和 Pdata,$max_D\ V(D,G)$就越小,表明 Pg 和 Pdata 越相似,其 $Div(Pg,Pdata)$ 也就越小。如此我们可以用$max_D\ V(D,G)$代替 $Div(Pg,Pdata)$ ,即生成器的训练目标转变成$G^*=arg\ min_G\ max_D\ V(G,D)$
GAN 训练技巧
-
GAN 以其难以训练而出名
-
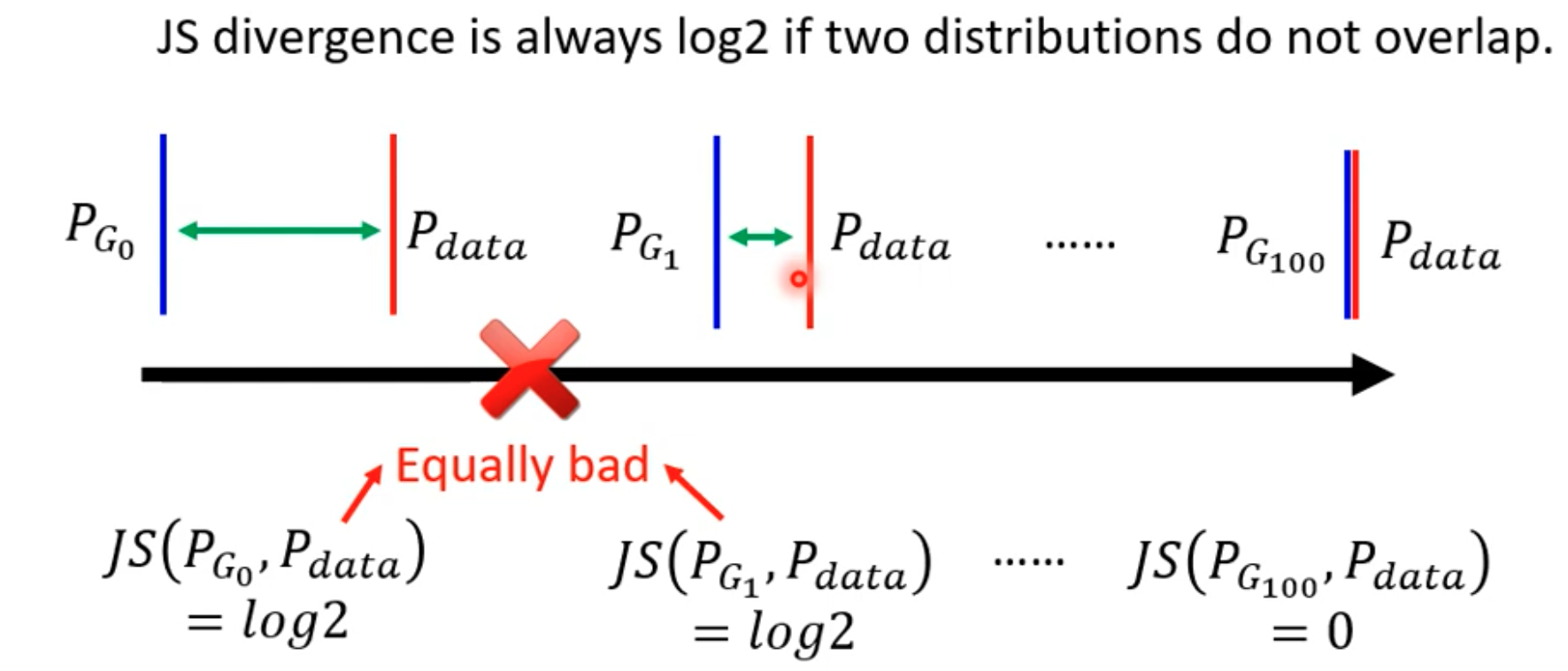
以 JS Divergence ,二分类判别器为例。在大部分使用中, Pg和 Pdata 只生成图片和真实图片数据集,问题在于
- 这些图片难有重叠部分。Pdata 和 Pg 是高维空间中的地位 manifold。例如随机图像是64*64*3维空间中随机取样的点,要构成一副有意义的面部图像是非常困难的,概率很小。Pdata 也是如此。所以 Pdata 和 Pg 很难有匹配的 case。
- 永远不知道 Pg 和 Pdata 的真实分布。即使 Pg 和 Pdata 有很大重叠,我们sample出来的case 也可能没有重叠
-
所以对于 JS Divergence,只要两个 case 没有重叠,Js 的结果都是 log2,即无论Pg 和 Pdata 的样本距离远近,只要没有完全重叠,JS 距离就会很大
-
二分类分类器很容易分辨生成图像和真实图像,那么损失函数$max_D\ V(D,G)$都会很大,无法有效表示 JS 距离
-
所以我们可以换成其他距离如 Wasserstein 距离,使之能够表示Pg 和 Pdata 的距离大小关系
-
另外,在 GAN 训练过程中,要求生成器和判别器都去收敛,一旦有一方出现问题,另一方也无法正常 train。但是在日常训练过程中,肯定会存在 loss 不降反升的情况,这需要我们让生成器和判别器棋逢对手
-
用 GAN 生成一段文字是最困难的。因为当生成器 Decoder 生成文本,判别器对文本打分。如果生成器做了更新,某个参数进行调整,但在文本生成时,我们使用输出的 max 获得文本 token,而 max 对参数的调整很难产生反应,也就是说最终判别器判别的文本没有区别,获得的打分也就是相同的,这样就很难训练,可以考虑使用强化学习训练
生成式模型还有 VAE、Flow-base Model。
GAN评估
评估生成图像质量
-
人工评价质量
-
使用人脸识别模型或者图像分类模型判断产生图像好坏
-
存在 Mode Collapse 问题:生成的图像比较真实,但是都非常类似真实图像的某一张图像
-
存在 Mode Dropping 问题:生成的图像分布只有真实图像的一部分,或者说生成的图像只围绕部分真实图像的特点生成
-
图片生成质量指标:Quality生成质量、Diversity 多样性
-
对于生成多样性问题,使用分类模型判断生成图像,查看分类的标签是否分布均匀
-
评估指标、
- Inception Score:使用 Inception 模型分类,评价 quality、diversity
- Frechet Inception Distance(FID):使用Inception 网络 softmax 前面的隐层向量表示当前图像,假设真实图像和真实图像都是高斯分布,所以计算每幅图像隐向量的 Frechet 距离
-
还会存在生成器直接生成原始图片,或者反转图片等极端情况
Conditional Generator
-
之前讲的生成器都是根据一个随机取样的 z 作为输入,生成想要的东西;现在我们需要对生成器添加一个 x 输入,操控生成器输出。
-
文字对图片的生成就是这种任务

-
这样的条件生成器也需要重新设计判别器,让判别器也读取输入的条件 x
-
这样的判别器就需要训练数据是成对的标注数据:
- 真实的图像和文本为 1;
- 输入的文本和生成的图像为 0;
- 输入的文本和真实图像不匹配也为 0
-
conditional GAN 也可以做给图像产生图像等等的任务
-
对于图片生成图片的任务,如果只是使用监督模型,那么可能存在刚开始那种多种情况都判正的情况,也就是说模型可能学到多种情况,平均起来就会导致模糊的图像导致生成的图像模糊;所以使用对抗生成模型 ,可以避免这种情况
这种 conditional GAN 需要成对的标注数据
GAN 用在 Unsurprised Leanring
-
图像风格转化任务,没有成对的资料来训练。
-
我们想将真实照片转成二次元照片,给定真实照片 Domain X,给定二次元照片 Domain Y,注意这里的二次元照片与真实照片没有一一对应的关系,双方都可能只是网络上的图片而已
-
类比普通的 GAN 的方式:
- 将真实照片Domain X 看成一个分布,从中取样作为 z 输入到生成器,生成器产生一个图像;然后判别器将生成图像与二次元图像对比。
- 但是这样产生的问题是生成器产生的图像与二次元图像在训练过程中仍然没有对应关系。极端些考虑,对于输入的真实图像,生成器可以从二次元图像中随便找一张图像作为生成图像,这对于判别器来说也可以训练的非常好。
-
Cycle GAN
-
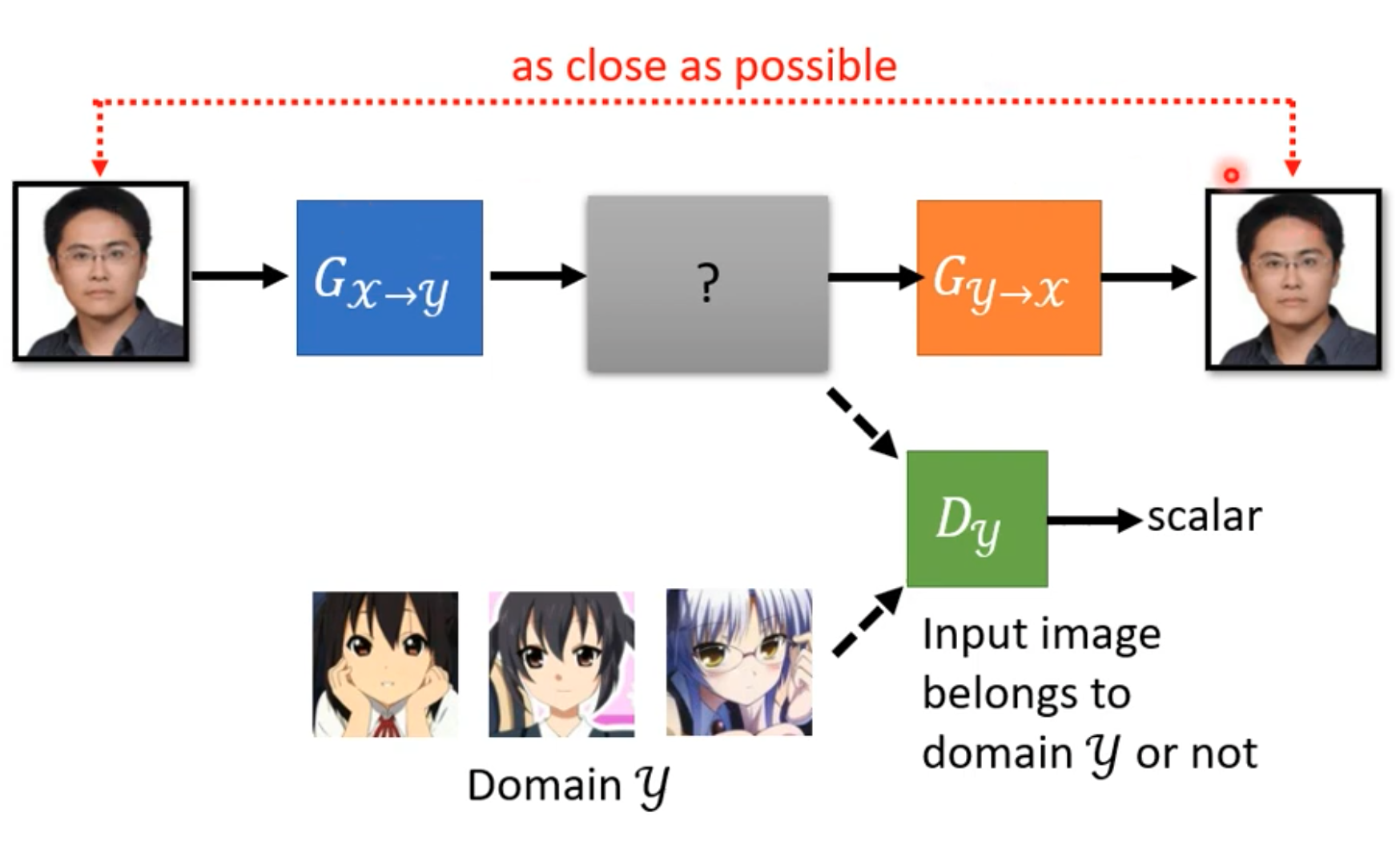
-
包含三个模型。第一个生成器就不能随便产生二次元图片。需要让第二个生成器返回到真实图像。这样可以学习到真实图像和二次元图像的关系。
-