先前无论 self-supervised learning 还是 autoencoder,本质上还是通过机器识别 label,本质上还是属于 supervised learning 的范式。
而Reinforcement Learning 面向的场景通常是,人类也不知道标注的 Label 是如何,不知如何评价 label 好坏,但是机器需要知道评判好坏的标准
一、何为 RL
RL本质同监督学习一样,也是要找一个Function,输入是观察到的环境变化Observation,输出是采取的动作Action,这个过程中,环境Environment会给这个 F 一个奖励Reward,告诉当前采取的动作是好是坏。这个过程的目标是最大话获得的奖励总和。
简化机器学习的三大步骤:
- 有一个存在未知数的 Function
- 从训练数据定义一个 Loss 函数
- 对 Loss 函数优化 F 的未知数使 Loss 最小化
类比以上,对于RL 的简化步骤:
- 同样具有未知数的函数,
-
扮演 Actor 的角色,称为 Policy Network
-
深度学习之前,他也可以是简单的规则方法。现在大部分是深度网络
-
输入是观察的状态,输出是每一个可以采取的行为分数softmax。本质和分类任务相同
-
最后按照各种动作的分数,sample 样例选择最终动作,sample 含义是随机产生动作
-
定义 Loss
- 整场游戏从开始第一步到最终结束,机器的每一步动作都会得到一个 Reward
- 游戏开始到结束称为 Episode,而所有步的 Reward综合称为 Total Reward
- loss 视为负 total Reward,训练目标是最大化 TotalReward
-
优化
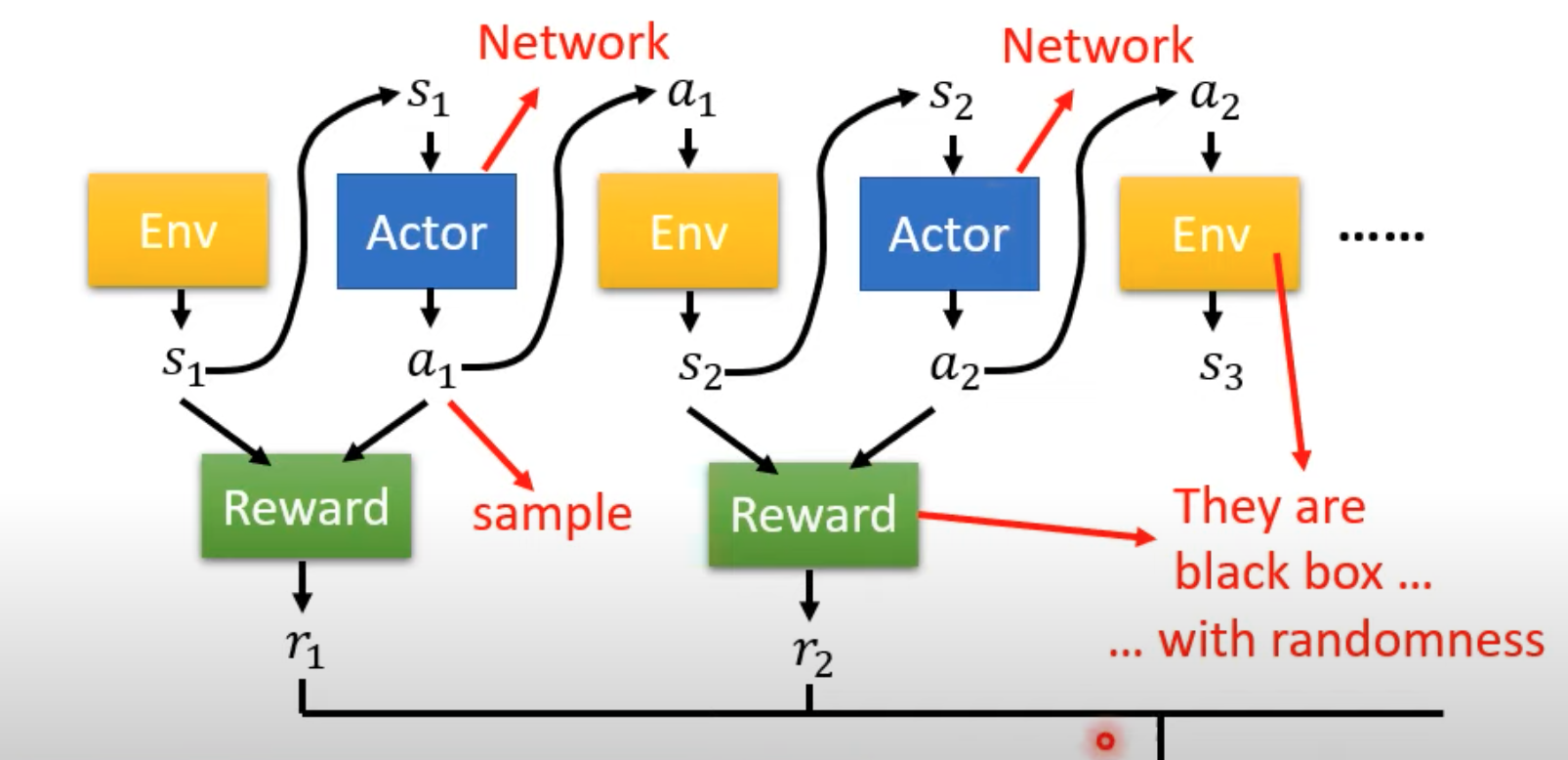
- 整个学习的过程有三个模块,Actor 是我们想要训练的网络,Env 提供网络输入的当前状态,Reward 提供系统采取行为后的奖励
- 随着游戏进行,对于 Actor 来讲,会产生一个序列 Trajectory(轨迹),$\tau={s_1,a_1,s_2,a_2,...,s_n,a_n}$。每次采取动作后产生奖励$r_i$,优化目标是使左右奖励和最大。
- 将整个过程看成序列或许可以使用 RNN 等序列模型处理优化最大奖励,但是这里存在问题无法轻易训练:
- Actor 在采取动作时存在随机性,不一定会采取得分最高的动作
- Env、Actor、Reward 不能看成整体来训练,Env、Reward 本质上并非网络,对于我们是黑盒,不知道其内部参数
- Env 或者 Reward 在有的场景下也可能具有随机性,即对于某状态 Actor 采取某动作,Env 的下一个状态不一定是确定的
-
从这三方面来看,RL 和 GAN 有异曲同工之妙:
- GAN 可以将 D 和 G 接到一起,固定 D 训练 G;而 RL 可以将 Actor 看成 G,将 Env 和 Reward 看成 D,因为两者的 Loss 一个是 Reward 的输出一个是 D 的输出,继而类比过来,我们可以将 Actor 和 Env、Reward 拼接来训练
- 但是与 GAN 不同的是,Env、Reward 都是黑盒,不是网络,因此不同对其优化
二、Policy Gradient优化方法
从训练一个 Actor 开始,将 Actor 的任务看做一个简单的分类或回归任务,即输入某个状态,输出采取某个措施的概率,此时先不考虑随机性问题,所有可能的行为类别已确定。这样对于 Actor 的 Loss 即可使用 CrossEntropy:$L=\sum e$;而假如对于某一状态,我们不想让 Actor 采取某项动作(可以采取其他剩余的动作),可以使用负 CrossEntropy:$L=-\sum \hat{e}$。
那么我们对于这样的分类问题,可以使用损失函数$L=\sum e-\sum\hat{e}$我们所需的训练数据是${s_i,\hat{a_i}},1\ or\ -1$,表示对于状态$s_i$,系统应该采取$\hat{a_i}$,或不应该采取$\hat{a_i}$
上述的训练数据是二分类问题。进一步,我们希望指明采取动作 a 的期望程度,则将其看成一个回归问题,(但与传统的回归问题还不完全相同,因为设计行为的类别与期望程度),此时的训练数据是${s_i,\hat{a_i}},Ai$,表示在状态$s_i$采取动作$\hat{a_i}$的期望是$A_i$,此时的损失函数即为$L=\sum A_ie_i$
所以本质上来看,Actor 的训练优化方法可视为分类回归模型的训练过程,只是其训练数据需要特别确定。但是训练数据中的具体行为$a_i$在实际中不太容易得到。这是 RL 的重点
1.如何获得训练数据的行为$\hat{A_i}$
RL 获得训练数据的重点是如何对每一个状态-动作对做出评价 A
-
首先随机初始化 Actor,参数为$\theta_0$
-
对于每一轮训练 Episode:
- 使用 Actor 获得一系列{si,ai}数据
- ☆使用某种方法计算每个行为动作对的期望分数 $A_i$
- 使用当前这轮的数据对计算 Loss
- 梯度下降更新一次参数:$\theta^i=\theta^{i-1}+\eta\frac{\partial L}{\partial \theta^{i-1}}$
这里要注意的是:
- 每一轮 Episode 中,才生成一系列训练数据。即训练数据不是一开始就有的,而是在每一轮 Episode 中生产的。
- 每一轮 Episode 中,只能更新一次参数的梯度下降,且只能是根据当前 Episode 的训练数据。因为第 i 轮 Episode 的训练数据是$\theta^i$的 Actor 产生的,只对$\theta^i$有关与$\theta^{i-1}$无关
所以 RL 的训练很费时间,较难训练。注意这里的 Episode 就只是做完一轮游戏。
整个训练过程中的重点是如何根据 Reward 或者 Env 获得数据对的 Ai。这里如果Ai 需要累积后续的 Reward,则可能需要进行结束当前游戏局后,倒推计算各步骤的 Ai
有如下几种思路:
- 直接使用{si,ai}的 Reward 作为 Ai
- 当前动作不止对当前有影响还会对之后有影响
- Reward Delay 问题:当前采取的动作可能在后续才会起作用获得高 Reward。所以当前得到较低 Reward 并不一定是坏事
- Cumulated Reward:使用当前动作到结束的所有 reward 和作为 Ai,$A_i=\sum_{k=i}^N R_k$
- 如果游戏很长,可能与最后结尾时第 N 个动作关系不大
- 所以可以加权值Discounted cumulated reward$G_i=\sum_{k=i}^N \gamma^{k-i} R_k,\gamma=0.9$
- Reward 是相对的,可能 Reward 都是正的,但是需要相对来看
- 对每个 Ai 加一个 baseline 避免全为正$A_i=\sum_{k=i}^N R_k-b$
注意:上述中的 G 和 A 并不完全等价。Ai 指动作好坏期望,Gi 指后续累积的 Reward。Gi 取正负代表奖励是正负,正或者负值无所谓,是相对来讲。而 Ai 则是评价标准,>0代表当前采取的动作较好,<0代表当前的措施比较糟糕
2.Off-Policy
上述边训练,边与环境交互的训练过程称为在线训练 On-policy
还可以一次性获得所有的交互动作对,然后在训练过程当中直接使用,这种训练方式称为 Off-Policy
- 这里要训练的 Actor,其训练数据的动作状态对是其他 Actor 与 Env 互动的结果
- 即只收集一次资料,始终使用以训练
有一个经典的 Off-policy 的训练策略 Proximal Policy Optimization(PPO),他的主要思想是需要让待训练的 Actor 意识到训练数据 Actor 的差距,
三、Actor-Critic
使用 Critic 也需要跟先前训练 Actor 一样训练出合适的 Critic
Critic 是用来预判当前 Actor对于某一状态s,后续可能获得的Discounted cumulated reward的好坏。
本质上是一个 value Function $V^\theta(s)$,输入是当前的状态 s,估计对于当前参数为$\theta$的 Vctor,直到游戏结束可能获得的累计 Reward:$G_i=\sum_{k=i}^N \gamma^{k-i} R_k,\gamma=0.9$输出是一个「期望值」。所以 Critic 工作就是未卜先知,只看当前状态就预测这一局游戏可能获得的 Reward。
Critic需要观察当前的 Actor,与当前的$\theta$的 Actor 一样。如果当前$\theta$ 的 Vector 效果不好,那 Critic 预估的累积 Reward 也相对较小
通过 Actor-Critic,我们就可以对上述的 Ai 计算思路进行升级,
1.Critic 训练方法
-
蒙特卡洛方法
- 将当前$\theta$状态的 Actor 与环境交互完成多局游戏,得到一笔训练资料。这些资料里面包含所有状态 s,也能够得知所有状态的累积 Reward G',
- 训练的方法就是让 Critic 能够对状态 s 的输出$V^\theta(s)$尽可能与s的实际 G‘相同
-
Temporal-difference(TD)方法
-
上面的蒙特卡洛方法要求获得的训练资料里玩完 完整的游戏,但很多情况下游戏玩完可能代价很大。TD 方法可以在不完成整局游戏的情况下训练 Critic
-
TD 方法需要当前状态的 Actor 交互,获得一系列的训练资料$...{s_t,a_t,r_t},{s_{t+1},a_{t+1},r_{t+1}}...$
-
观察 $V^\theta(s_t)$的计算公式:
$ V^\theta(s_t)=r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+... $
$ V^\theta(s_{t+1})=r_{t+1}+\gamma r_{t+2}+\gamma^2 r_{t+3}+... $
$ V^\theta(s_t)=\gamma V^\theta(s_{t+1})+r_t $
根据 $s_t 和 s_{t+1}$间的关系,我们希望对于训练资料中的数据,$V^\theta(s_t)-\gamma V^\theta(s_{t+1})\iff r_t$尽可能成立
-
上面的两个方法对于同样的训练资料可能对于同一状态s,训练出不同的Critic
我们训练 Critic 时,sample 的训练资料应该能尽可能包含所有状态,以及所有状态下的所有可能动作
2.Critic 作用
有了 Critic,可能帮助我们更好的计算 $\hat{A_i}$
对于上述的$\hat{A_i}$的计算方法,利用 Critic 我们可以继续改进:
-
对于${s_t,a_t},令A_i=G'_i-V^\theta(S_i)$
-
对于方法 3: $A_i=\sum_{k=i}^N R_k-b$,其中的 b 的值不好确定。一个比较好的设法是令$b=V^\theta(S_i)$
-
此时的 Ai就可以评价当前状态采取某措施的好坏程度。这里的$V^\theta(s_t)$是所有可能动作的平均期望
-
比较好的原因是$V^\theta(s_t)$代表了当前状态 st 能够得到累积 Reward 的期望值。
-
而且在 st 状态下,Actor 不一定执行 at 动作,而 $V^\theta(s_t)$包含了可能st采取的所有动作的期望。回顾下 Actor 设计当初输出的是各个动作的概率分布,希望他具备动作选取的随机性,甚至随机性越大越好。如此$V^\theta(s_t)$ 代表采取所有可能的动作获得的 Reward 期望
-
这样以来,对于${s_t,a_t},A_t=G'_t-V^\theta(s_t)$,$G'_t$代表 st 状态采取动作 at 得到的累积 Reward,$V^\theta(s_t)$代表了st采取所有可能动作获得的累积 Reward 的期望,二者相减。若 At>0,说明当前采取动作 at 的效果好于所有动作的平均效果;反之说明当前动作的Reward 小于 随机采取动作得到的 Reward
-
-
对于${s_t,a_t},令A_t=r_t+V^\theta(s_{t+1})-V^\theta(s_t)$
-
令$r_t+V^\theta(s_{t+1})=G't$
-
上面的方法 4,由于$V^\theta(s_t)$是统计值,而 $G'_t$是一次训练时得到的确切值。将 G‘t也换成统计值更有效
-
简单来说,G‘t代表了 st 下采取动作 at 获得的累积 Reward,$V^\theta(s_t)$代表 st 下采取所有动作可能获得的 累积 Reward 的平均期望值。
-
那么对于 st,对于 G‘t的统计值,可以利用$s_{t+1}$状态的统计值和 采取动作 at 获得的 rt 来表示
-
此时 At 表示st 状态下,采取 at 得到的 rt以及后续采取随机动作获得的累积 Reward 比当前 st 状态下随机采取动作获得的累积 Reward,是否更好或更坏
-
大名鼎鼎的 Advantage Actor-Critic 方法
-
具体训练时,我们可以共用部分参数来训练 Actor 和 Critic。Actor 输出是不同动作的分布,Critic 输出是累积 Reward 的值
-