
Abstract
SwimTransformer 目的是将Transformer引入到CV领域,作为CV的通用backbone,甚至替代CNN。考虑到文本任务和图像任务的不同特点,SwimTransformer的主要思路是基于「滑动窗口」的「分层」Transformer。Swim约束self-attention在非重叠窗口计算,另外允许跨窗口联系,具有更高效率,而且复杂度与图像大小线性相关。实验证明,将Swim代替CNN在多种CV任务上效果都有所提升。Swim代码链接
Introduction
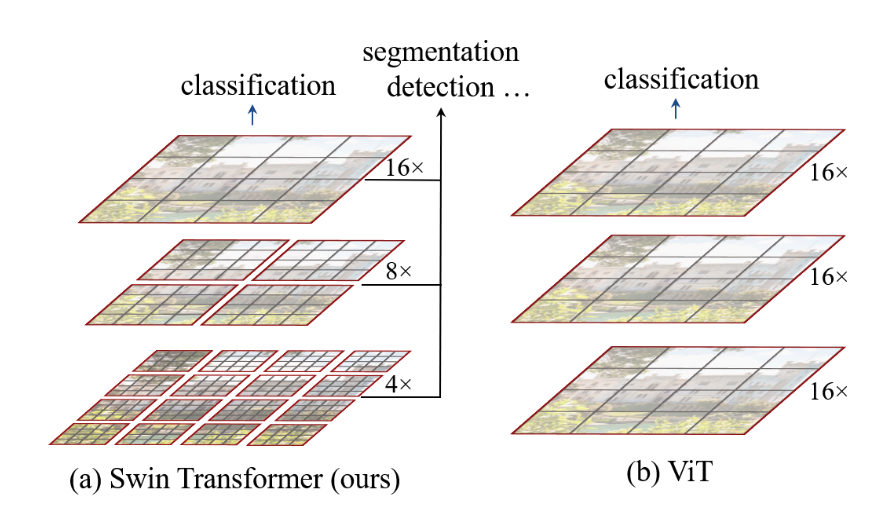
Swim类似多层CNN逐层计算归结相邻的“Attention”区域。每层中,划分多个local windows,每个local window包含多个patch。local window是最小单位,类似于卷积核?每层中self attention计算一个patch中的多个local window。因此会有线性复杂度。而先前的Visual Transformer是整个图像的self attention,平方复杂度。
Transformer从NLP领域迁移到CV领域的主要挑战在于两种模态的差异。其一是处理规模:文本的基本处理单位是一句话的token,而图像的单位是大规模像素,token规模可以固定,但图像像素却不能。其二是分辨率:Transformer对于处理高分辨率图像的复杂度是平方的。基于此提出的Swim Transformer,能够构造层次特征映射,且具备线性复杂度。
此外,Swim的关键设计在于「滑动窗口」。滑动窗口在当前层的local windowns之间构建联系。
Method
整体过程
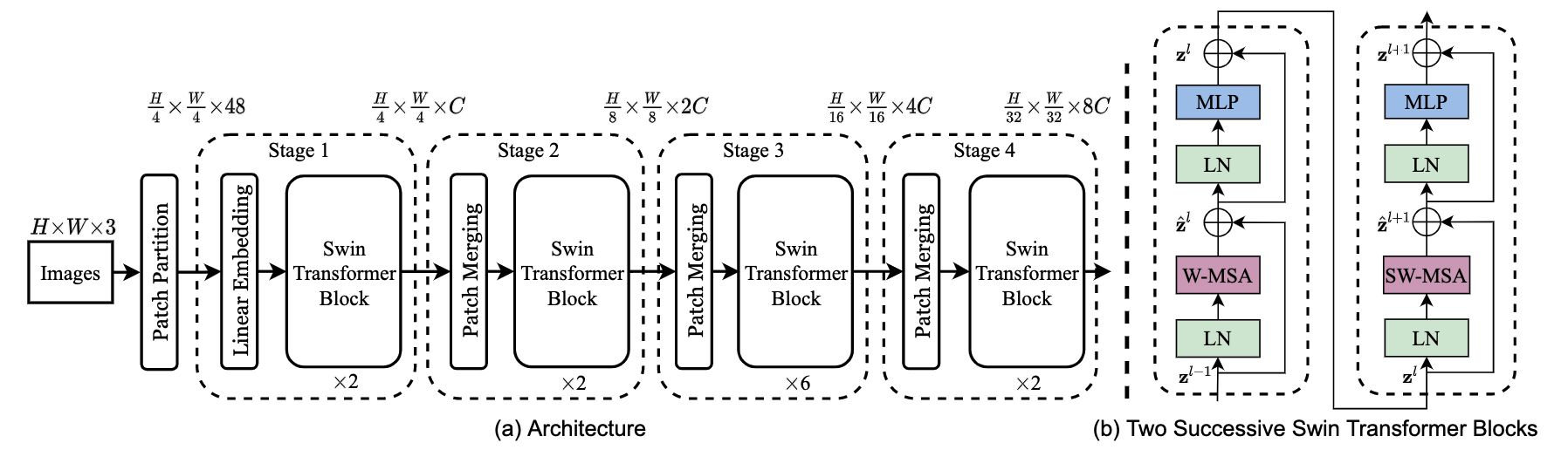
- 对于RGB图像,分成多个$4\times 4$ 大小的patch,这里的patch作用类似于token。将patch concat成$4\times 4\times 3=48$作为当前patch的特征,接入全连接后经过SwimT Block,可以映射到任意维特征。这样,图像被划分为 $\frac{H}{4}\times \frac{W}{4}\times C$的特征向量。
- 随着网络增加,设置Patch merge layer,对同一个local window内,也就是相邻的四个patch整合特征信息,同时增加每个token特征维
- 随后,SwimT Block负责对划分的local window内的patch(也就是token)作Attention计算。这里的SwimT Block分为两种类型:普通窗口的MSA(Masked Self-Attention)和滑动窗口的MSA
- W-MSA:计算同一window内多个patch的Attention
- SW-MSA:窗口在window间移动捕获window之间的Attention
滑动窗口SwimT
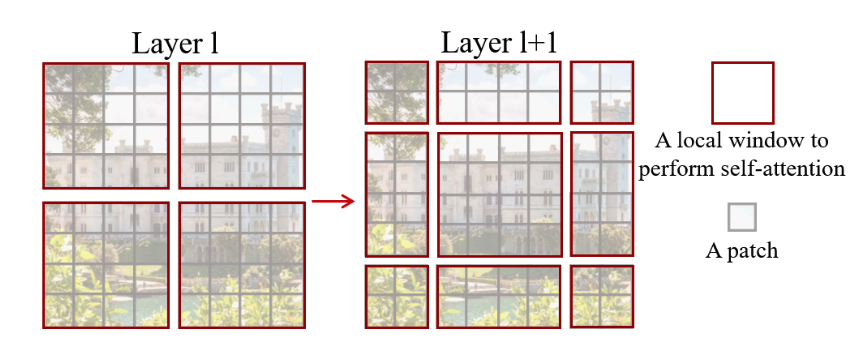 将整个图像的patch划分多个window可以有效降低复杂度,但是单纯的对window计算,没有办法获得window之间的信息,由此引入滑动窗口机制。
将整个图像的patch划分多个window可以有效降低复杂度,但是单纯的对window计算,没有办法获得window之间的信息,由此引入滑动窗口机制。
在两个相邻的SwimT Block间,如上图所示,前后会移动window位置,具体移动策略下文阐述。移动后,同样对window内的patch作计算,此时的计算结果就包含了先前相邻window的共同信息。
具体的移动策略可称之为Cycle shift。前后SwimT Block中window大小是不变的,将window区域作移动操作,但是移动后,window数量会增多,而且window区域的大小发生改变,这就需要对不相邻的window互相补充,然后计算对应的MASK,只计算相邻window的信息。
Cycle shift的移动策略参考自知乎

滑动窗口的意义
与SwimT工作最相关的是ViT,它同样试图将Transformer引入CV,提出对图像划分patch作Attention。这样存在的问题是对图像全局的patch作计算,复杂度高。
SwimT改进思路是将划分的patch分组成不同的window,参考CNN引入局部性思想:以window为单位计算Attention。然而如此不能想ViT那样获得全局信息,所以计算完local window后,设计滑动窗口来获得相邻window的信息。又凭借分层网络的特点,随着网络深度增加,利用滑动窗口可以获得图像的全局信息。
SwimT工作目标是设计一种CV的通用骨干网络代替CNN,而在各种CV任务中将CNN换为SwimT,实现更高的的SOTA。
读这篇文章,是想学习下Best Paper的行文逻辑,确实牛哇~