A Review on Deep Learning Techniques for Video Prediction
Abstract
基于深度学习的视频预测技术正成为一个 promising 的研究方向。本质上,视频预测作为一种自监督学习任务,需要具备从自然视频序列中提取有意义的潜在模式的表示学习的能力,这些潜在模式主要是视频序列中的时空序列特征。
1、Introduction
通常来讲,对未来事件的预测是智能决策系统的关键组成部分。与人相比,机器对视频未来的预测受到多方面影响,如遮挡、视角移动、光照条件、杂波或物体变形。
视频预测主要应用于机器人领域、自动驾驶领域、行为预测领域等。对于机器人领域,基于有条件的视频预测,机器人可以实现基于视觉的动作决策和路径规划,甚至提高基于强化学习的机器人在未知环境中的能力。在自动驾驶领域,对交通情况的轨迹预测可以有效估计未来事件。其他应用场景也包括:实例/语义分割预测、异常事件检测、气象预测和视频差值等方面。
2、Video Prediction 介绍
问题描述
从 predictive coding paradigm角度来看,视频预测任务可以定义为根据给定的 n 帧图像 X,预测后续 m 帧图像 Y。即给定视频序列$X=(X_{t-n},...,X_{t-1},X_t)$,其中$X_t\in R^{w \times h\times c}$,$w,h,c$代表视频帧的长宽以及色彩通道数目,目标是预测接下来 m 帧图像$Y=(\hat{Y_{t+1}},\hat{Y_{t+2}},...,\hat{Y_{t+m}})。
需要注意的是,与其他的视频/图像生成任务不同,视频预测的图像帧生成需要根据先前帧的表示作为条件。模型需要具备充分的表示学习的能力,将先前帧的特征充分学习到,才能实现效果良好的预测
时间维度处理
不同于静态图像,视频序列包含了在时间维度上的复杂变换和动作模式。模型需要能够提取描述视频序列动作的视觉特征,对视频序列的时序相关性建模,提高预测帧的动作连续性。
随机性处理
在给定上下文图像,预测物体后续状态的任务中,通常会假设理想的物理环境的场景,这样物体可能会匀速运动,实现准确预测。使用这种假设来缩小预测空间以处理不确定性。然而这种假设对于自然视频是不适合的。因为通常来讲,未来状态的可能性存在多种可能的分布模式,即存在多种有效的可能的未来状态。
目前多数深度学习模型是确定性的预测,因为对于大多数场景,如车辆轨迹、合成数据集(Moving MINST)和视频游戏等,短时间内可以视为确定性事件。这些场景与自然视频并不完全相同。然而,当产生多种等可能性的预测时,确定性模型会学着「平均」多种可能的输出。这种「平均」效果取决于损失函数的选择,在实际输出中通常表现为换面的模糊,特别是在长时预测场景中。
解决平均的模糊输出可以构建针对性的损失函数来减轻模糊效果,但是本质上确定性模型无法处理真实世界中的混沌状态,因此有必要在模型中引入不确定性。
损失函数的设计
在常见的预测任务中的损失函数:Pixel-wise losses(如 Cross Entropy)、$l_2、l_1$以及 MSE loss 等在确定性场景(合成视频、游戏视频)中可以有效使用,但在自然视频中难以获得好的效果。例如在多种等可能的输出情况下,Pixel-wise loss 会通过模糊预测来适应不确定性,该损失函数假设数据服从高斯分布。即 MSE 等 loss 会通过平均像素点来最小化 MSE误差,因为该误差是全局最优值,从而避免了精细的细节,如面部表情等微妙的特征,这些特征会被认为成特征。换句话说,确定性的损失函数在模糊预测中会平均多个合理的结果。问题在于设计损失函数设计多峰分布(multimodal distribution)。
许多视频预测任务的优化目标是在不确定场景时减小模糊性。主要方式可以包括:改进损失函数;基于对抗的训练方式;更高维度特征空间表述问题以优化训练;探索概率替代方案。
然而,尽管已取得较好的处理模糊问题的效果,现有的多数损失函数都是基于距离的优化。有效处理回归均值问题仍未被有效解决
3、基本模型结构
卷积模型CNN
由于视觉图像预测任务,CNN 是相关研究的基础模型,但不同于静态图像任务,CNN 在帧序列图像中受限于帧内和帧之间的依赖问题。
这里的短程帧依赖性问题受限于 CNN 的感受野大小。已有工作解决思路有:堆叠更多卷积层、增大卷积核、线性组合多个尺度的卷积核、膨胀卷积核、扩大感受野与池化层二次采用等方式。
另一方面,传统 CNN 建模图像内部像素的联系,而无法建模帧与帧之间的特征,这一问题主要采用 3D-CNN 解决,他可以捕获时序一致性,解决时空序列中的多尺度预测问题。
循环模型 RNN
RNN 被设计用来对序列数据建模时空特征表示。RNN 的常见问题在于处理长时依赖的梯度消失与爆炸问题。
生成模型
判别模型主要学习类别之间的决策界限,而生成模型学习独立类别的不均匀分布。判别式模型在于学习条件概率$p(y|x)$,生成模型在于学习联合概率$p(x,y)$,或者确实 label y 情况下的$p(x)$。
生成模型的目标是:给定训练数据x,生成新的样例$\hat{x}$使其与训练数据同分布。训练的目标即是通过显示(VAE)或隐式(GAN)模型,根据输入数据估计密度函数来实现。在视频预测任务中,生成模型通常用户生成多种可行预测来处理后续帧的不确定性,而非单一的结果。根据生成模型的种类,可以分为以下三种主要类别:
- 显式密度建模
(1)以 PixelRNN 是和 PixelCNN 为代表。
是一种完全可视信念网络(FVBNs),明确定义可处理密度,并将联合分布 p(x)估计为像素上条件分布的成绩。通俗的讲,该类模型专注于像素的生成,像素生成转换为一个连续的建模问题,下一帧图像中像素有先前同样位置的像素确定。该类模型将帧序列中同一位置的像素进行处理,使用序列模型如 LSTM 等建立像素前后的时序依赖关系。总的来讲,该方法输出图像中每个位置的像素值的分布,目的是最大化生成数据与训练数据的相似度
(2)VAE(变分自编码器)
VAE 模型的原理是对输入的数据自动编码和重构,捕获包含最有意义的变化因素的低纬表示。
- 隐式密度建模
GAN
基于生成器和辨别器的对抗模型。常规 GAN 的生成器从随机噪声中采样,是一种无条件的模型。对于视频预测任务,生成器和辨别器需要引入额外的条件信息,如先前预测等,这种方法称为conditional GAN(CGAN)。使用 CGAN 能够让输入数据帧和预测数据帧的时空一致性得到保证。
然而一方面,对抗训练不够稳定,容易崩溃;另一方面,也可能由于损失函数的问题,导致预测模糊
对 VAE 和 GAN 的额外理解
VAE 和 GAN 的基本目标一致——希望构建一个从隐变量 Z 生成目标数据 X 的模型g,令 X=g(Z)。这里的 Z 可以视为服从某种分布 p(Z)中取样得到的随机向量。也就是说,我们构造 Encoder 和 Decoder,其中 Encoder 是根据训练数据 X 的分布,构建Z 的分布p(Z),从中取样得到隐变量 Z;Decoder 根据取样得到的 Z 生成数据$\hat{X}$,最终目标是使得生成数据$\hat{X}$与训练数据 X 尽可能相似。
VAE 和 GAN 的区别在于衡量生成数据和输入数据相似度的处理方法上。首先,由于生成器的本质是在训练数据的分布和生成数据的分布上计算的,本质是概率分布的相似度计算。衡量两个分布的相似性我们通常使用 KL散度或 JS 散度衡量。但是计算前提是需要知道两个分布的概率密度函数,目前我们拥有的只是一些训练数据样本和生成数据样本。当然我们可以通过频率计数估计样本的分布。
对于 GAN 来讲,在估计生成样本分布与训练样本分布的相似度方面,直接使用神经网络拟合,也即判别器模型。
4、相关数据集
根据预测任务的具体划分,视频数据集可以包括如下种类:动作和人类姿势识别、驾驶和城市场景理解、物体和视频分类、视频预测
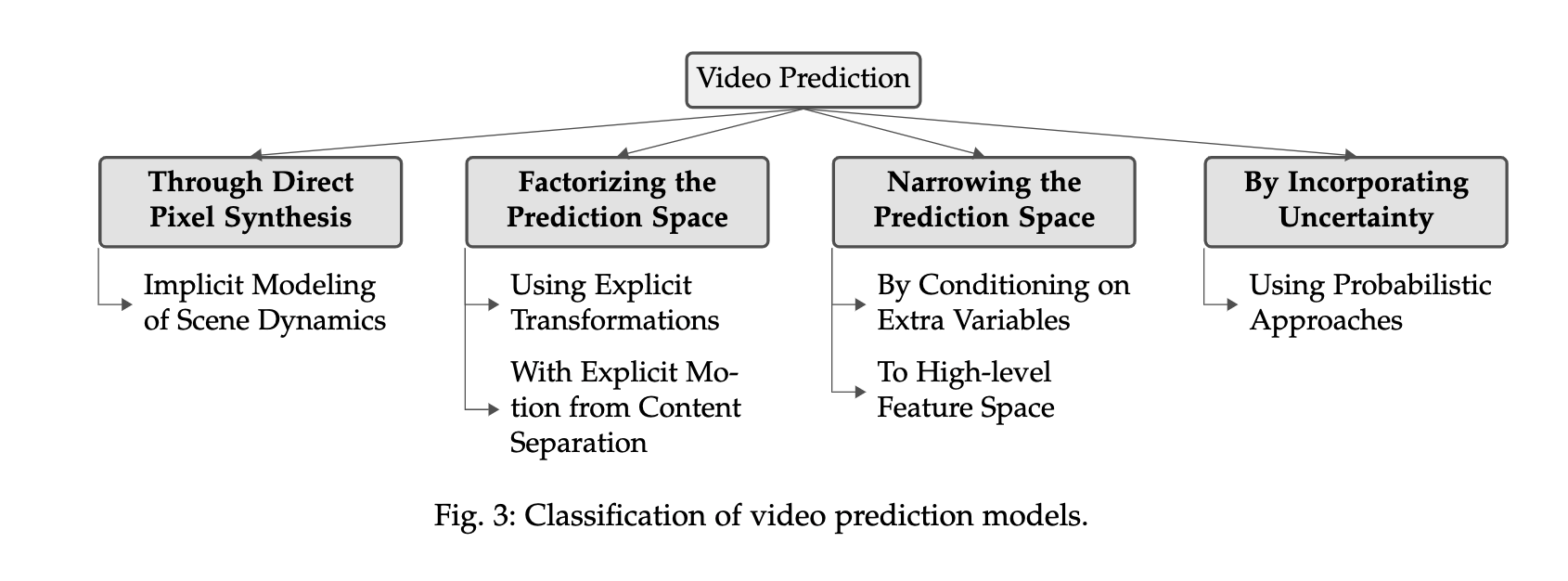
5、主要方法
关于视频预测任务,早期方法通过隐式的建模动态建景和低级细节,(1)直接预测原始的像素。这种方法的缺点是难以对高维的像素空间进行有效学习。对原始方法的改进思想演化为减少监督力度和特征降维。一种方法可以(2)从视觉内容中分离出变化的区域,例如分解预测空间。具体可有两种方法:建模帧之间的明确变化区域;将运动与视觉区域分离与组合。另一种方法是(3)缩小预测空间,具体而言可以通过对额外变量的预测来缩小输出空间;在高维空间中表述问题。以上都是对预测任务的简化,还有一种研究目标是(4)将不确定性引入未来帧的预测,对不确定性环境建模,以降低模糊效果